Es el código que nuestro cuerpo usa para convertir las instrucciones contenidas en nuestro ADN en los materiales esenciales de la vida.
Normalmente se forma usando los «codones» que se encuentran en el ARNm, ya que el ARNm es el mensajero que transporta información desde el ADN al sitio de la síntesis de proteínas.
Todo en nuestras células finalmente se construye en base al código genético. Nuestra información hereditaria, es decir, la información que se transmite de padres a hijos, se almacena en forma de ADN.
Ese ADN se usa para construir ARN, proteínas y finalmente células, tejidos y órganos.
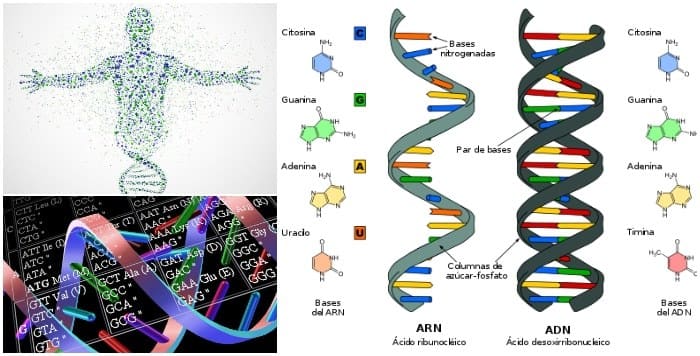
Al igual que el código binario, el ADN usa un lenguaje químico con solo unas pocas letras para almacenar información de una manera muy eficiente. Mientras que el binario usa solo unos y ceros, el ADN tiene cuatro letras que son los cuatro nucleótidos:
- Adenina.
- Citosina.
- Guanina.
- Timina/Uracilo.
La timina y el uracilo son muy similares entre sí, excepto que la «timina» es un poco más estable y se usa en el ADN. El uracilo se usa en el ARN y tiene todas las mismas propiedades que la timina, excepto que es un poco más propenso a mutar.
Esto no importa en el ARN, ya que nuevas copias de ARN pueden producirse a partir del ADN en cualquier momento, y la mayoría de las moléculas de ARN son destruidas intencionalmente por la célula poco tiempo después de su producción para que la célula no desperdicie recursos produciendo proteínas innecesarias de viejas moléculas de ARN.
Juntas, estas cuatro letras de A, C, G y T/U se usan para «deletrear» instrucciones codificadas para cada aminoácido, así como otras instrucciones como «comenzar la transcripción » y «detener la transcripción».
Las instrucciones para «comenzar», «detener» o para un aminoácido dado son «leídas» por la célula en bloques de tres letras llamadas «codones».
Cuando hablamos de «codones», generalmente nos referimos a codones en ARNm: el «ARN mensajero» que se hace copiando la información en el ADN.
Por esa razón, hablamos de codones hechos de ARN, que usa uracilo, en lugar del código de ADN original que usa timina.
Cada aminoácido está representado en nuestras instrucciones genéticas por uno o más codones.
Una de las evidencias más notables del ancestro común de toda la vida en la tierra de un antepasado único es el hecho de que todos los organismos usan el mismo código genético para traducir el ADN en aminoácidos.
Hay algunas pequeñas excepciones que se encuentran, pero el código genético es lo suficientemente similar en todos los organismos que cuando un gen de una planta o medusa se inyecta en una célula de mamífero, por ejemplo, la célula de mamífero leerá el gen de la misma manera y ¡construye el mismo producto que la planta original o las medusas!
Función del código genético
El código genético permite que las células contengan una cantidad de información inmensa.
Considere esto: un óvulo fecundado microscópicamente, siguiendo las instrucciones contenidas en su código genético, puede producir un ser humano que incluso tenga una personalidad y comportamientos similares a los de sus padres. ¡Hay mucha información ahí!
El desarrollo del código genético fue vital porque permitía a los seres vivos producir de forma fiable los productos necesarios para su supervivencia, y pasaba instrucciones sobre cómo hacer lo mismo a la siguiente generación.
Cuando una célula intenta reproducirse, una de las primeras cosas que hace es hacer una copia de su ADN. Esta es la fase «S» del ciclo celular, que significa «Síntesis» de una nueva copia del ADN de la célula.
La información codificada en el ADN se conserva mediante el emparejamiento específico de las bases de ADN entre sí. Adenina solo se unirá con Timina, Citosina, Guanina, etc.
Eso significa que cuando una célula quiere copiar su ADN, todo lo que tiene que hacer es separar las dos cadenas de la doble hélice y alinear los nucleótidos con los que las bases del ADN existente «quieren» emparejarse.
Este emparejamiento de bases específico asegura que el nuevo filamento del compañero contendrá la misma secuencia de pares de bases, el mismo «código», que el anterior. Cada doble hélice resultante contiene una cadena de ADN viejo emparejado con una cadena de ADN nuevo.
Estas nuevas hélices dobles serán heredadas por dos células hijas. Cuando llega el momento de que esas células hijas se reproduzcan, cada hebra de estas nuevas hélices dobles actúa como plantillas para una nueva doble hélice.
Cuando llega el momento en que una célula «lee» las instrucciones contenidas en su ADN, utiliza el mismo principio de vinculación específica de pares. El ARN es muy similar al ADN, y cada base de ARN se une específicamente a una base de ADN. El uracilo se une a la adenina, la citosina a la guanina, etc.
Esto significa que, al igual que la replicación del ADN, la información en el ADN se transfiere con precisión al ARN siempre que la cadena de ARN resultante esté compuesta por las bases que se unen específicamente con las bases en el ADN.
A veces, la cadena de ARN en sí misma puede ser el producto final. Las estructuras hechas de ARN desempeñan funciones importantes en nosotros mismos, como el ensamblaje de proteínas, la regulación de la expresión génica y la catalización de la formación de proteínas.
De hecho, algunos científicos piensan que la primera vida en la tierra podría haber estado compuesta principalmente de ARN.
Esto se debe a que el ARN puede almacenar información en sus pares de bases como el ADN, pero también puede realizar algunas funciones enzimáticas y reguladoras.
En la mayoría de los casos, sin embargo, el ARN pasa a ser transcrito en una proteína. Usando el aminoácido «bloques de construcción de la vida», nuestras células pueden construir máquinas casi proteínicas para casi cualquier propósito, desde fibras musculares hasta neurotransmisores y enzimas digestivas.
En la transcripción de proteínas, los codones de ARN que se transcribieron a partir del ADN son «leídos» por un ribosoma.
El ribosoma encuentra el ARN de transferencia apropiado (ARNt) con «anti-codones» que son complementarios a los codones en el ARN mensajero (ARNm) que se ha transcrito a partir del ADN.
Los ribosomas catalizan la formación de enlaces peptídicos entre los aminoácidos a medida que «leen» cada codón en el ARNm. Al final del proceso, tiene una cadena de aminoácidos especificada por el ADN, es decir, una proteína
Otros bloques de construcción de la vida, como los azúcares y los lípidos, a su vez son creados por las proteínas. ¡De esta manera, la información contenida en el ADN se transforma en todos los materiales de la vida, utilizando el código genético!
Tipos de mutaciones genéticas
Debido a que el código genético contiene la información para la vida, los errores en el ADN de un organismo pueden tener consecuencias catastróficas.
Pueden ocurrir errores durante la replicación del ADN si se agrega el par de bases incorrecto a una cadena de ADN, si se omite una base o si se agrega una base adicional.
En raras ocasiones, estos errores pueden ser útiles: ¡la versión «errónea» del ADN puede funcionar mejor que la original o tener una función completamente nueva! En ese caso, la nueva versión puede tener más éxito, y su proveedor puede superar a los operadores de la versión anterior en la población.
Esta extensión de nuevos rasgos en toda una población es la forma en que funciona la evolución.
Mutaciones silenciosas y codificación redundante
En algunos casos, las mutaciones genéticas pueden no tener ningún efecto en el producto final de una proteína. Esto se debe a que, como se ve en la tabla anterior, la mayoría de los aminoácidos están conectados a más de un codón.
La glicina, por ejemplo, está codificada por los codones GGA, GGC, GGG y GGU. Una mutación que dé como resultado que el nucleótido incorrecto se utilice para la última letra del codón de glicina, entonces, no tendría importancia.
Un codón que comience en «GG» aún codificará la glicina, sin importar qué letra fue la última utilizada.
Se cree que el uso de codones múltiples para el mismo aminoácido es un mecanismo que se desarrolló con el tiempo para minimizar la posibilidad de que una pequeña mutación cause problemas a un organismo.
Mutación sin sentido
En una mutación sin sentido, la sustitución de un par de bases por un par de bases incorrecto durante la replicación del ADN da como resultado el uso del aminoácido incorrecto en una proteína.
Esto puede tener un efecto pequeño en un organismo, o uno grande, dependiendo de qué tan importante sea el aminoácido para la función de su proteína y en cual de esta se efectúa.
Esto se puede pensar como la construcción de muebles. ¿Qué tan malo sería si usaras la pieza incorrecta para atornillar la pata de una silla en su lugar?
Si usaste un tornillo en lugar de un clavo, los dos son probablemente lo suficientemente parecidos como para que la pierna de la silla permanezca encendida, pero si tratas de usar, por ejemplo, un cojín para unir la pierna a la silla, tu silla no funcionará muy bien.
Una mutación sin sentido puede dar como resultado una enzima casi tan buena como la versión normal, o una enzima que no funciona en absoluto.
Se produce una mutación sin sentido cuando el par de bases incorrecto se usa durante la replicación del ADN, pero cuando el codón resultante no codifica un aminoácido incorrecto.
En cambio, este error crea un codón de detención u otra información que es indescifrable para la celda. Como resultado, el ribosoma deja de funcionar en esa proteína y todos los codones posteriores no se transcriben.
Las mutaciones sin sentido conducen a proteínas incompletas, que pueden funcionar muy mal o no funcionar en absoluto. ¡Imagínese si dejara de armar una silla a la mitad!
Supresión
En una mutación por deleción, una o más bases de ADN no se copian durante la replicación del ADN. Las mutaciones de eliminación vienen en una gran variedad de tamaños: ¡puede faltar un solo par de bases, o puede faltar una pieza grande de un cromosoma!
Las mutaciones más pequeñas no siempre son menos dañinas. La pérdida de solo una o dos bases puede dar como resultado una mutación del marco de lectura que daña un gen crucial.
Por el contrario, las mutaciones de deleción más grandes pueden ser fatales, o pueden dar como resultado una discapacidad, como en el síndrome de DiGeorge y otras afecciones que resultan de la eliminación de parte de un cromosoma.
La razón de esto es que el ADN se parece mucho al código fuente de la computadora, una pieza de código puede ser crucial para que el sistema se encienda, mientras que otras partes del código podrían garantizar que un sitio web se vea bien o se cargue rápidamente.
Dependiendo de la función del fragmento de código que se elimine o se modifique, un pequeño cambio puede tener consecuencias catastróficas, o una alteración aparentemente grande del código uno puede dar como resultado un sistema que es un poco impreciso.
Inserción
Una mutación de inserción se produce cuando uno o más nucleótidos se añaden erróneamente a una cadena de ADN en crecimiento durante la replicación del ADN. En raras ocasiones, largos tramos de ADN pueden agregarse incorrectamente en el medio de un gen.
Al igual que una mutación sin sentido, el impacto de esto puede variar. La adición de un aminoácido innecesario en una proteína puede hacer que la proteína sea solo ligeramente menos eficiente; o puede paralizarlo.
Considere lo que sucedería con su silla si le agregara una pieza de madera al azar que las instrucciones no requerían. ¡Los resultados pueden variar mucho dependiendo del tamaño, la forma y la ubicación de la pieza extra!
Duplicación
Una mutación de duplicación ocurre cuando un segmento de ADN se replica accidentalmente dos o más veces. Al igual que las otras mutaciones enumeradas anteriormente, estas pueden tener efectos leves, o pueden ser catastróficas.
Imagine que su silla tiene dos espaldares, dos asientos u ocho patas. Una pequeña duplicación y la silla aún puede ser utilizable, aunque un poco extraña o incómoda. ¡Pero si la silla tuviera, por ejemplo, seis asientos unidos entre sí, podría volverse inútil rápidamente para su propósito previsto!
Mutación con desplazamiento de la pauta de lectura
Una mutación del marco de lectura es un subtipo de mutaciones de inserción, eliminación y duplicación.
En una mutación del marco de lectura, se eliminan o insertan uno o dos aminoácidos, lo que resulta en un desplazamiento del «marco» que utiliza el ribosoma para indicar dónde se detiene un codón y comienza el siguiente.
Este tipo de error puede ser especialmente peligroso porque hace que se malinterpreten todos los codones que ocurren después del error. Típicamente, cada aminoácido agregado a la proteína después de la mutación del marco de lectura es incorrecto.
Imagínese si estaba leyendo un libro, pero en algún momento durante la redacción, ocurrió un error, de modo que cada letra posterior cambió una letra más adelante en el alfabeto.
Una palabra que se suponía que debía leer «letra» se convertiría de repente en «mfuuft». Esto es aproximadamente lo que sucede en una mutación del marco de lectura.